 Overflow of techniques
Overflow of techniques
Abstract
End-to-end test cases that exercise the application under test via its user interface (UI) are known to be hard for developers to read and understand; consequently, diagnosing failures in these tests and maintaining them can be tedious. Techniques for computing natural-language descriptions of test cases can help increase test readability. However, so far, such techniques have been developed for unit test cases; they are not applicable to end-to-end test cases.
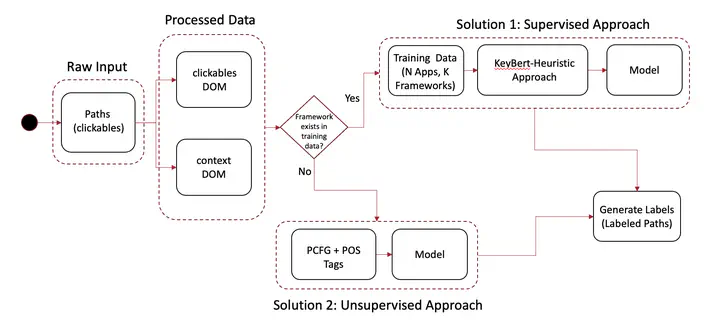
In this paper, we focus on the problem of computing natural-language labels for the steps of end-to-end UI test cases for web applications. We present two techniques that apply natural-language processing to information available in the browser document object model (DOM). The first technique is an instance of a supervised approach in which labeling-relevant DOM attributes are ranked via manual analysis and fed into label computation. However, supervised approach requires a training dataset. So we propose the second technique, which is unsupervised: it leverages probabilistic context-free grammar learning to compute dominant DOM attributes automatically. We implemented these techniques, along with two simpler baseline techniques, in a tool called CrawLabel (available as a plugin to Crawljax, a state-of-the-art UI test-generation tool for web applications) and evaluated their effectiveness on open-source web applications. Our results indicate that the supervised approach can achieve precision, recall, and F1-score of 83.38, 60.64, and 66.40, respectively. The unsupervised approach, although less effective, is competitive, achieving scores of 72.37, 58.12, and 59.77. We highlight key results and discuss the implications of our findings.
Yu Liu
PhD student at UT Austin
My research interests include software testing, programming languages, and machine learning